For decades, banking compliance has operated on a reactive model. Financial institutions monitored transactions, reviewed reports, investigated anomalies, and responded to regulatory requirements after the fact. Compliance teams relied heavily on manual workflows, periodic audits, rule-based systems, and fragmented monitoring processes to manage growing regulatory complexity.But the compliance landscape is changing rapidly.
As regulatory expectations intensify and financial ecosystems become increasingly digital, traditional monitoring approaches are struggling to keep pace. Banks are now exploring a new operational paradigm—one where AI systems move beyond passive monitoring and toward autonomous oversight. This shift is redefining how financial institutions approach compliance, risk management, fraud detection, and operational resilience.
Why Traditional Compliance Models Are Reaching Their Limits
Modern banks process millions of transactions, customer interactions, and operational events every day. At the same time, regulatory frameworks continue to evolve across critical areas such as anti-money laundering (AML), Know Your Customer (KYC), fraud detection, transaction monitoring, data privacy, risk reporting, and operational governance. Managing these interconnected requirements has become increasingly challenging.
Traditional compliance infrastructures were never designed for this level of scale and complexity. Many institutions still rely on siloed compliance systems, static rule engines, manual investigations, batch-based reviews, and retrospective auditing practices. While these approaches have served organizations for years, they often struggle to provide the speed, flexibility, and visibility needed in today's digital banking environment.
As transaction volumes continue to grow, these legacy models contribute to high false-positive rates, delayed risk detection, rising operational costs, compliance fatigue, limited scalability, and a lack of real-time visibility into emerging risks. The gap between compliance demands and operational capacity is widening, forcing organizations to rethink how oversight is performed.
The Shift Toward Autonomous Oversight
Autonomous oversight represents the next evolution of compliance operations.
Instead of relying solely on human teams to monitor and interpret risk signals, banks are increasingly deploying AI-driven systems capable of continuously monitoring transactions, detecting anomalies, validating compliance controls, investigating suspicious activity, generating regulatory reports, escalating high-risk events, and coordinating remediation workflows.
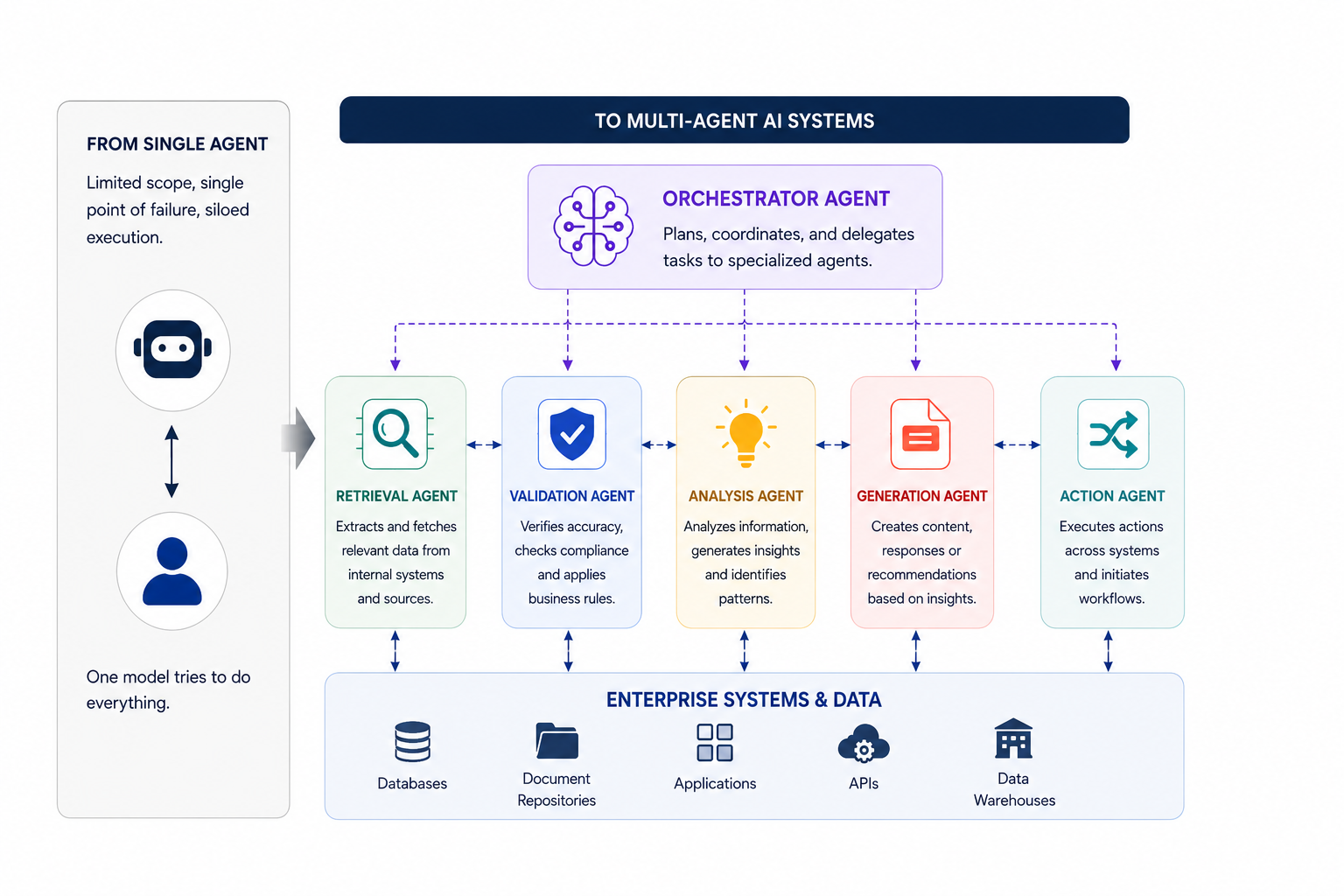
These systems do far more than automate individual tasks. They orchestrate end-to-end compliance processes with greater speed, consistency, and contextual intelligence. At the center of this transformation is Agentic AI.
What Makes Agentic AI Different?
Traditional AI systems are typically designed to respond to prompts or execute predefined workflows. Agentic AI introduces a fundamentally different approach by enabling systems to reason, plan, coordinate, and take actions autonomously within established governance boundaries.
In banking compliance environments, multiple specialized AI agents can work together across the compliance ecosystem:
- Monitoring agents track transactions and activities in real time.
- Risk agents identify unusual behavioral patterns and emerging threats.
- Investigation agents gather contextual evidence and analyze anomalies.
- Reporting agents generate audit-ready documentation and regulatory summaries.
- Governance agents validate policy adherence and control effectiveness.
- Escalation agents route high-risk cases for human review.
Rather than depending on a single monolithic AI model, banks can deploy specialized agents that collaborate intelligently. This creates a more adaptive, scalable, and resilient compliance architecture capable of responding to constantly changing regulatory and operational conditions.
From Reactive Compliance to Continuous Compliance
One of the most significant advantages of autonomous oversight is the transition from periodic monitoring to continuous compliance.
Traditionally, compliance reviews occur on a daily, weekly, monthly, or quarterly basis. However, risks emerge in real time. By the time a periodic review identifies an issue, the impact may already be significant.
AI-driven oversight systems continuously evaluate operational activity as it occurs, enabling earlier detection of suspicious behavior, faster response times, reduced compliance gaps, stronger regulatory readiness, and greater operational resilience. Instead of waiting for scheduled reviews, organizations gain a real-time understanding of risk exposure across their operations.
Continuous compliance also enhances transparency by generating ongoing audit trails and monitoring histories throughout business processes. For regulators, this level of visibility is becoming increasingly valuable as expectations around accountability and risk management continue to rise.
Reducing False Positives and Investigation Burden
False positives remain one of the most persistent challenges in banking compliance. Traditional rule-based monitoring systems often generate large volumes of alerts that require manual review, consuming significant time and resources.
As a result, compliance professionals frequently spend considerable effort investigating cases that ultimately present little or no actual risk.
Agentic AI can dramatically improve this process by correlating information across multiple data sources, understanding behavioral context, learning from historical investigations, prioritizing genuinely high-risk events, and automating the closure of low-risk cases.
This intelligent prioritization enables compliance analysts to focus their expertise on the investigations that matter most. The result is a more efficient compliance function that delivers stronger risk outcomes while reducing operational burden.
Strengthening Regulatory Reporting
Regulatory reporting continues to be one of the most resource-intensive functions within financial services. Institutions must gather information from multiple systems, validate data accuracy, maintain documentation, and meet increasingly stringent reporting timelines.
AI-driven oversight systems help streamline these processes by continuously validating data quality, tracking regulatory changes, generating dynamic compliance summaries, maintaining audit-ready evidence, and automating report preparation workflows.
Rather than treating reporting as a periodic activity, banks can move toward an always-on state of reporting readiness. This approach improves consistency, reduces manual effort, and enables organizations to respond more effectively to regulatory inquiries.
Why Governance Still Matters
Despite the rise of autonomous systems, human oversight remains essential.
Compliance decisions often require regulatory interpretation, ethical judgment, escalation management, customer impact assessment, and legal review. These responsibilities cannot be fully delegated to automated systems.
The objective is not to remove humans from compliance operations but to augment human expertise with intelligent systems capable of managing scale and complexity more effectively.
This makes governance a critical component of AI-driven compliance. Banks must establish robust frameworks that include human-in-the-loop controls, explainability mechanisms, auditability standards, access governance policies, model monitoring practices, bias detection processes, and clearly defined escalation protocols.
Without these safeguards, autonomous systems can introduce new operational and regulatory risks. Trust, transparency, and accountability remain foundational to successful adoption.
The Future of Banking Compliance
The future of banking compliance will be defined less by isolated automation and more by intelligent orchestration.
Banks are steadily moving toward ecosystems where AI agents continuously monitor operational environments, identify risks proactively, adapt to changing regulations, and maintain real-time compliance readiness. Human teams, meanwhile, will spend less time on repetitive reviews and more time focusing on strategic oversight and decision-making.
This shift represents a fundamental transformation:
- From static controls to adaptive intelligence.
- From reactive investigations to predictive oversight.
- From fragmented systems to coordinated compliance ecosystems.
In many ways, compliance is evolving from a cost center into a strategic resilience capability that supports trust, growth, and long-term operational stability.
Final Thoughts
As regulatory complexity continues to increase, banks can no longer rely solely on manual monitoring models built for slower and simpler environments.
Autonomous oversight powered by Agentic AI offers a path toward:
- Scalable compliance operations
- Faster risk detection
- Improved reporting accuracy
- Reduced operational burden
- Greater regulatory confidence
However, technology alone is not enough. The institutions that succeed will be those that combine intelligent automation with strong governance, transparency, and human accountability.Because the future of banking compliance is not fully autonomous.
It is intelligently supervised, continuously adaptive, and built on trusted oversight at scale.